In order to help us plan how we reopen our museums we
created an online public survey which we have publicised via our social media
channels, our website, community networks, and e-newsletter.
Our reopening will be phased and will begin with Bristol
Museum and Art Gallery (BMAG) and M Shed. A date for reopening has not yet been
confirmed.
The following is a summary of 10 key findings from the
public survey:
Findings are based on feedback between 22/05 – 10/06 from c.360
responses
There is demand for our sites to reopen. 75% of respondents say they will visit; 59% told us BMAG or M Shed are in their top 3 indoor public spaces to visit once the lockdown is lifted.
There is higher demand from respondents for BMAG to reopen than M Shed (67% vs. 33%)
Levels of trust in the museums to provide a safe visit are very high. The average trust rating is 4.5 out of 5.
84% of respondents told us they would like to visit for between 30 minutes and 2 hours.
33% of respondents told us they are likely to visit with children under 16
The top four reasons for visiting the museums following the lockdown would be 1) to see a temporary exhibition 22%; 2) To get out of the house 17%; 3) To go somewhere familiar 16%; and 4) To learn something 16%.
Respondents are generally happy to see additional restrictions and measures put in place: 85% are happy to pre-book free tickets; 71% would like to see ‘child free’ time slots; and 72% would like to see time slots for ‘over 70s and vulnerable adults’.
The main change that would put off visitors is the closing of our current temporary exhibitions Wildlife Photgrapher of the Year (M Shed) and Do You Believe Magic? (BMAG) – 36% told us they would be put off visiting by this change.
The primary suggestions for increasing safety during visits are: increased hygiene, limits on numbers, social distancing, and increased staff visibility.
Acorn Analysis (segmentation) of respondents shows there is a slightly lower than typical representation of Audiences form disadvantaged background – 13% compared to 21% average across physical sites.(Actions are in place or planned to address this.)
The survey will remain open till at least the end of June 2020. So far the responses have been really useful in telling us what our audiences need from us to reopen our sites in a safe and welcoming way.
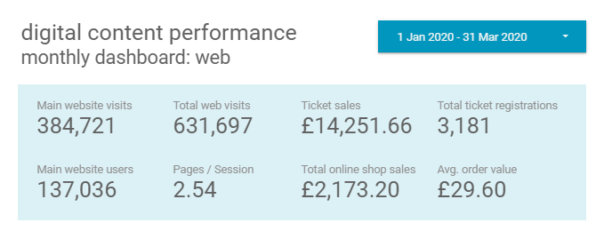
Bristol Culture receives an average of 2.5 million yearly visits to its websites (not including social media). Additionally, we have different demographics specific to each social media channel, which reflect the nature of the content and how users interact with the platform features offered.
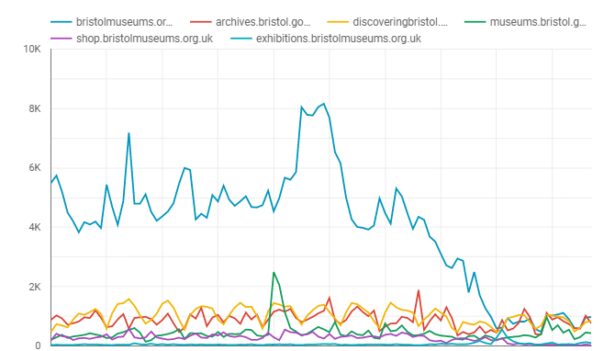
Since March 13th visits to the bristolmuseums.org.uk have fallen off sharply from a baseline of 4000/day to under 1000/day as of 6th April. This unprecedented change in website visitors is a reflection of a large scale change in user behaviour which we need to understand, presumably – due to people no longer searching to find out about visiting the museum in person, due to enforced social distancing measures. It remains to be seen how patterns of online behaviour will change in the coming weeks, however, it appears we have a new baseline which more closely matches our other websites that are more about museum objects and subject matter than physical exhibitions and events.
You can explore this graph interactively using the following link:
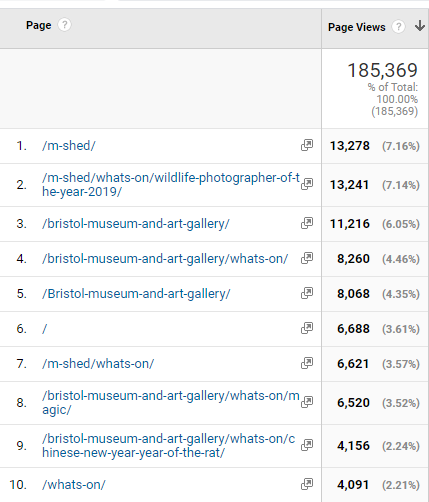
The top 10 most visited pages in January on bristolmuseums.org.uk feature our venue homepages, specific exhibitions and our events listings
online stats January 2020
During Lockdown
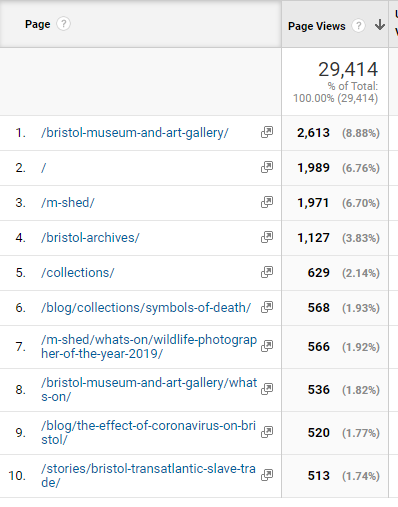
From March-April we are seeing visits to our blog pages, our online stories and our collections pages feature in the top 10 most visited.
online stats March 16th-April 9th
Digital Content Strategy
Internally, we have been developing a digital content strategy to help us develop and publish content in a more systematic way. The effect of CV-19 has meant we have had to fast track this process to deal with a large demand for publishing new online content. The challenge we are faced with is how to remain true to our longer-term digital aims, whilst tackling the expectations to do more digitally. In practice, we have had to rapidly transform to a new way of working with colleagues, collaborating remotely, and develop a new fast track system of developing and signing off digital content. This has required the team to work in different ways both internally, distributing tasks between us, but also externally across departments so that our content development workflow is more transparent.
A key principle of our audience development plan is to understand and improve relationships with our audiences (physical and digital). This involves avoiding the idea that everything is for ‘everyone’. Instead of recognising that different activities suit different audiences. We seek to use data from a range of sources (rather than assumptions) to underpin decisions about how to meet the needs and wants of our audiences.
Quarantine online audiences
Since the implementation of strict quarantine measures by the Government on Tuesday 24th March – audiences’ needs have changed.
Families at home with school-age children (4 – 18) who are now home-schooling during term-time.
Retired people with access to computers/smart-phones who may be isolated and exploring online content for the first time.
People of all ages in high-risk groups advised not to leave their homes for at least the next 12 weeks.
People quarantining who may be lonely/anxious/angry/bored/curious or looking for opportunities to self-educate.
Possible new international audiences under quarantine restrictions.
Whilst our plummeting online visitors overall tells us one story – we now have data to tell us there is a baseline of people who are visiting our web pages regularly and this audience needs consideration. Potentially a new audience with new needs but also a core group of digitally engaged visitors who are seeking content in one form or another.
Some things we need to be thinking about when it comes to our digital content:
What audiences are we trying to reach and what platforms are they using?
What reach are we aiming for and what are other museums doing – we don’t necessarily want to publish content that is already out there. What’s our USP?
What can we realistically do, and do well with limited resources?
What format will any resources take and where will they ‘live’?
What’s our content schedule – will we be able to keep producing this stuff if we’ve grown an audience for it once we’re open again? When will we review this content and retire if/when it’s out of date?
We need to be thinking about doing things well (or not doing them at all – social media platforms have ways of working out what good content is, and will penalise us if we keep posting things that get low engagement. A vicious cycle)
We want to engage with a relevant conversation, rather than simply broadcast or repurpose what we have (though in practice we may only have resource to repurpose content)
Submitting ideas/requests for digital content during Quarantine period
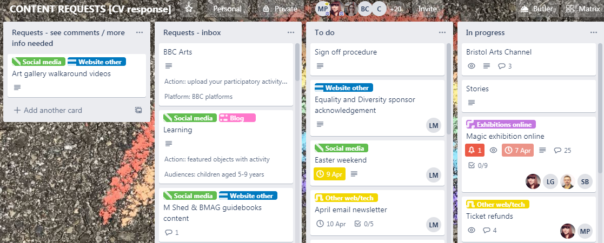
We are already familiar with using trello to manage business processes so we quickly created a new board for content suggestions. This trello-ised what had been developing organically for some time, but mainly in the minds of digital and marketing teams.
Content development Process in trello
STEP 1: An idea for a new piece of digital output is suggested, written up and emailed to the digital team, and then added to the Digital Content Requests Trello.
STEP2: The suggestion is then broken down / augmented with the following information (detailed below), and added as fields to the trello card
STEP 3: This list of suggestions is circulated amongst staff on the sign off panel, for comments.
STEP 4: The card is either progressed into the To Do List, or moved back to “more info needed / see comments” list.
The following information is required in order to move a digital content suggestion forward:
Description: Top level description about what the proposal is
Content: What form does the content take? Do we already have the digital assets required or do we need to develop or repurpose and create new content? What guidelines are available around the formats needed?
Resource: What staff are required to develop the content, who has access to upload and publish it?
Audiences: Which online audiences is this for and what is their user need?
Primary platform: Where will the content live, and for how long?
Amplification: How will it be shared?
Success: What is the desired impact / behaviour / outcome?
Opportunities
Experimentation
New and emerging content types: The lockdown period could be an opportunity to try a range of different approaches without worrying too much about their place in the long term strategy.
Online events programme
Now we can only do digital-or-nothing, we need to look at opportunities for live streaming events. Where there is no audience – how do we build enough digital audiences to know and be interested in this if we did go down that route. Related to above – online family/ adult workshops, a lot of this is happening now, are they working, how long will people be interested?
Collaborating with Bristol Cultural organisations
With other cultural organisations in Bristol facing similar situations, we’ll be looking to collaborate on exploring:
What is the online cultural landscape of Bristol?
Collaborative cultural response to Corona
A curated, city wide approach
Working with digital producers on user research questions
Similar to the Culture ‘Flash Sale’
Scheduled content in May
Arts Council England business plan
Those projects are at risk of not being able to be delivered – can digital offer a way to do these in a different way?
Service / Museum topical issues
How can we create an online audience to move forward our decolonisation and climate change discussions?
Family digital engagement
We’ll be working with the public programming team to develop content for a family audience
Examples of museum services with online content responding well to quarantine situation
a) they have a clear message about the Corona virus situation
b) they have adjusted their landing pages to point visitors to online content.
British Museum https://www.britishmuseum.org/closure Up front message from Director about situation, message of valuing audiences, website not that polished, does it matter?
Tate Gallery https://www.tate.org.uk/ No clear upfront message but 4 highlighted options can be enjoyed from home/may be useful for parents too
Rijksmuseum, Amsterdam https://www.rijksmuseum.nl/en Good simple landing message ‘Rijksmuseum from home. Always open online’. 360 degree virtual tours of most popular galleries, ability to zoom in on individual paintings (although not labels).
Birmingham Museums https://www.birminghammuseums.org.uk/ Closure message (although could be more up front), virtual tours, collections search and NHS cup sales foregrounded
Glasgow Museums https://www.glasgowlife.org.uk/museums explaining work going on behind the scenes “we are working hard to create online versions of the activities and programmes 75% of Glaswegians enjoy and rely on.”
Examples of museums with good online content generally
The Development Team typically manages around £12,800 in donations per month through ‘individual giving’ which goes to our charity, Bristol Museums Development Trust. This is from a variety of income streams including donation boxes, contactless kiosks, Welcome Desks and donations on exhibition tickets. Closure of our venues means this valuable income stream is lost. To mitigate this, we need to integrate fundraising ‘asks’ into our online offers. For example, when we promote our online exhibitions, ask for a donation and link back to our online donation page.
The Development Team will work with the Digital and Marketing teams to understand plans and opportunities for digital content and scope out where and how to place fundraising messages across our platforms. We will work together to weave fundraising messages into the promotion of our online offers, across social media, as well as embed ‘asks’ within our website.
Next Steps:
Clearly, there will be long-lasting effects from the pandemic and they’ll sweep through our statistics and data dashboards for some time. However – working collaboratively across teams, responding to change and using data to improve online services are our digital raison d’etre – we’ll use the opportunity as a new channel for 2020 onwards instead of just a temporary fix .
My name is Steffan Le Prince, I am a Digital Assistant and am primarily based at M Shed, having started the role 2 months ago. My main focus is fixing the digital interactives in the museum, I also support colleagues with technical problems and help set up and roll out new digital tech and exhibitions here, lately I’ve been working on new digital signage using the Signagelive content management system.
Living in Bristol since 6 years of age, it’s spiritually where I’m from. I have a varied educational and previous work background, I studied Computer Games Technology at University and also completed a higher education course in Music Production. I have worked from a delivery driver, to a go kart centre marshal, to a mobile arcade games area provider for events to a remote technical support agent over the phone. This role allows me to draw from all these experiences (fixing the interactives can be surprisingly similar to fixing a game!).
I was thrown in at the deep end on my first day, when the WiFi in shop and box office of M Shed went down, helping to troubleshoot this half way through my induction conversation. This straight away was so interesting and hands on, quite a challenge for me and co-Digital Assistant Jack Evans at Bristol Museum and Art Gallery, where the same WiFi issue also happened at the same time.
I love working for Bristol Culture in the Digital Team, the role combines the troubleshooting aspect that I have enjoyed in previous work and I find it really rewarding fixing technical issues and being part of the team at a local museum, M-Shed is a good fit for me as Bristol life, music, people, places and street art have all have a big impact on my life.
My name is Jack Evans and I’m one of the new Digital Assistants at Bristol Culture. I am currently based at Bristol Museum & Art Gallery and I help the Museum by maintaining the technology we have in the galleries.
I am from Dursley, Gloucestershire and have lived in the South West for most of my life. After secondary school, I stayed on to do A-Levels in Computing, ICT, and Art and then went on to do a Foundation Diploma in Art and Design at SGS College. After which I went to University and as of this Summer I finished my degree in Fine Art at Falmouth University in Cornwall, where I specialised in Video Art, Photography and Installations. I did a lot of my work there using AV, Projections in particular, I put on a video art exhibition with other artists at a gallery in Falmouth and throughout my degree collaborated on many AV based art pieces.
I have always been very “techy” and have been building and fixing tech since my early teenage years. After doing my degree I still wanted to be connected to art and culture, but I also wanted to utilise my technical side. So I am incredibly happy that I am part of the Digital Team here at Bristol Culture and able to contribute to the work we do here. So far I and my colleague Steffan, who is also a new Digital Assistant, have been experimenting with ways of auditing and managing all the tech across the Museums. This will allow us to know the specifics of the technology and what tech we have in the galleries and tech available to replace older exhibits and start creating new and improved interactives throughout the next year.
I have been maintaining and fixing the interactives we have at Bristol Museum & Art Gallery, yesterday I helped Zahid, our Content Designer fix a screen in the Magic exhibition gallery which required altering the exhibition structure and threading cables to the screen from above. We are starting to have fewer issues here at Bristol Museum and Art Gallery with interactives, as I’m now here, I’m identifying and solving issues allowing us as a team to have more time to come up with new ideas and improvements and spend less time on maintenance.
I have also been cataloguing interactives we have in the galleries and I am starting to collect content from old interactives so we can begin to refresh old interactives. I have also helped the Curatorial team figure out what technology to purchase or rent for an upcoming exhibit next year, exhibition problem solving is something I’ve always wanted to do in my career so I was very happy to be a part of that process. My experience over the past few weeks here have been great, I have loved helping out and keeping the tech running for visitors, I look forward to more projects in the future and I am very proud to work here.
One of our digital team objectives for this year is to do more with data, to collect, share and use it in order to better understand our audiences, their behaviour and their needs. Online, Google analytics provides us with a huge amount of information on our website visitors, and we are only just beginning to scratch the surface of this powerful tool. But for physical visitors, once they come through our doors their behaviour in our buildings largely remains a mystery. We have automatic people counters that tell us the volume of physical visits, but we don’t know how many of these visitors make their way up to the top floor, how long they stay, and how they spend their time. On a basic level, we would like to know which of our temporary exhibitions on the upper floors drive most traffic, but what further insight could we get from more data?
We provide self complete visitor surveys via ipads in the front hall of our museums, and we can manually watch and record behaviour – but are there opportunities for automated processing and sensors to start collecting this information in a way which we can use and without infringing on people’s privacy? What are the variables that we could monitor?
Hack Time!
We like to collaborate, and welcome the opportunity to work with technical people to try things out, so the invitation to join the yearly “Lockdown” hack day at Zengenti – a 2 day event where staff form teams to work on non-work related problems. This gave us a good chance to try out some potential solutions to in gallery sensors. Armed with Raspberry Pis, webcams, an array of open source tech (and the obligatory beer) the challenge to come up with a system that can glean useful data about museum visitors at a low cost and using fairly standard infrastructure.
Team:
Atti Munir – Zengenti
Dan Badham – Zengenti
Joe Collins – Zengenti
Ant Doyle – Zengenti
Nic Kilby – Zangenti
Kyle Roberts – Zengenti
Mark Pajak – Bristol Museum
Mission:
Can we build a prototype sensor that can give us useful data on visitor behaviour in our galleries?
What are the variables that we would like to know?
Can AI automate the processing of data to provide us with useful insights?
Given GDPR,what are the privacy considerations?
Is it possible to build a compliant and secure system that provides us with useful data without breaching privacy rights of our visitors?
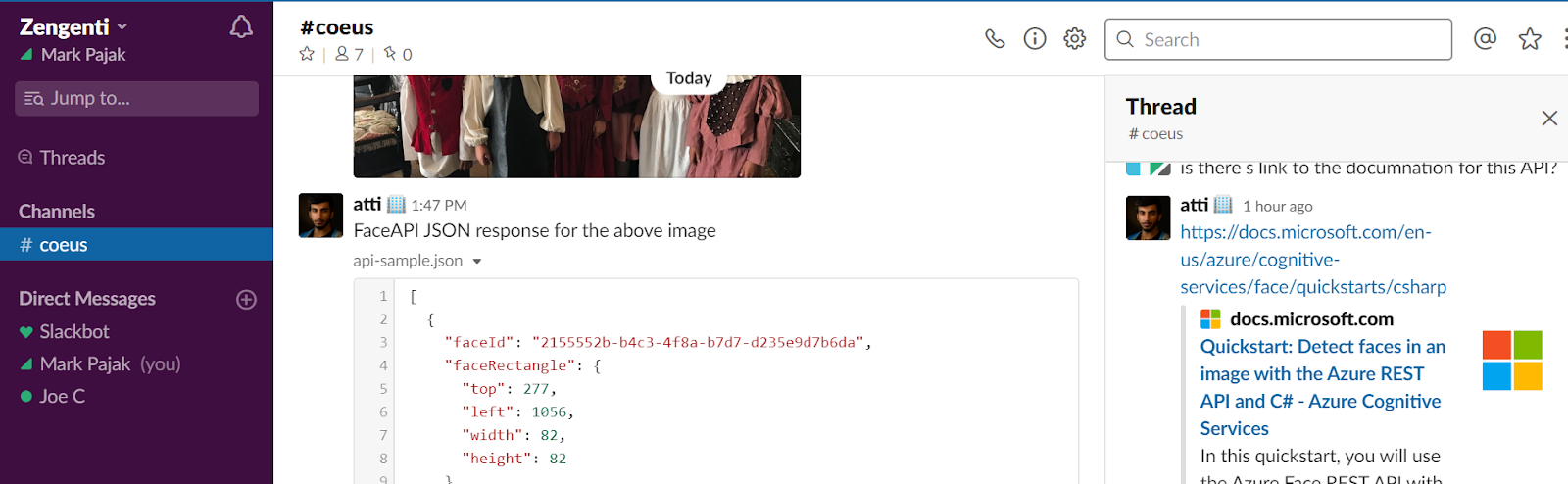
Face API
The Microsoft Azure Face API is an online “cognitive service” that is capable of detecting and comparing human faces, and returning an image analysis containing data on age, gender, facial features and emotion. This could potentially give us a “happy-o-meter” for an exhibition or something that told us the distribution of ages over time or across different spaces. This sort of information would be useful for evaluating exhibition displays, or when improving how we use internal spaces for the public.
Face detection: finding faces within an image.
Face verification: providing a likeliness that the same face appears in 2 images.
Clearly, there are positive and negative ramifications of this technology as highlighted by Facebook’s use of facial recognition to automatically tag photos, which has raised privacy concerns. The automated one-to-many ‘matching’ of real-time images of people with a curated ‘watchlist’ of facial images is possible with the same technology, but this is not what we are trying to do – we just want anonymised information that can not be related back to any specific person. Whilst hack days are about experimentation and the scope is fairly open to build a rough prototype – we should spend time reviewing how regulations such as GDPR affect this technology because by nature it is a risky area even for purposes of research.
How are museums currently using facial recognition?
Cooper Hewitt Smithsonian Design Museum have used it to create artistic installations using computer analysis of the emotional state of visitors to an exhibit.
GDPR and the collecting and processing of personal data
The general data protection regulations focus on the collection of personal data and how it is stored or processed in some way. It defines the various players as data controllers, data processors and data subjects, giving more rights to subjects about how their personal data is used. The concerns and risks around protecting personal data mean more stringent measures need to be taken when storing or processing it, with some categories of data including biometric data considered to be sensitive and so subject to extra scrutiny.
Personal data could be any data that could be used to uniquely identify a person including name, email address, location, ip address etc, but also photographs containing identifiable faces, and therefore video.
Following GDPR guidelines we have already reviewed how we obtain consent when taking photographs of visitors, either individually or as part of an event. Potentially any system that records or photographs people via webcams will be subject to the same policy – meaning we’d need to get consent – this could cause practical problems for deploying such a system, but the subtleties of precisely how we collect, store and process images are important, particularly when we might be calling upon cloud based services for the image analysis.
In our hypothesised solution, we will be hooking up a webcam to take snapshots of exhibition visitors which will then be presented to the image analysis engine. Since images are considered personal data, we would be classed as data controllers, and anything we do with those images as data processing, even if we are not storing the images locally or in the cloud.
Furthermore – the returned analysis of the images would be classed as biometric data under GDPR and as such we would need explicit consent from visitors to the processing of their images for this specific purpose – non consented biometric processing is not allowed.
We therefore need to be particularly careful in anything we do that might involve images of faces even if we are only converting them to anonymised demographic data without any possibility to trace the data to an individual. The problem also occurs if we want to track the same person across several places – we need to be able to identify the same face in 2 images.
This means that whilst our project may identify the potential of currently available technology to give us useful data – we can’t deploy it in a live environment without consent. Still – we could run an experimental area in the museum where we ask for consent for visitors to be filmed for research purposes, as part of an exhibition. We’d need to assess whether the benefits of the research outweigh the effort of gaining consent.
This raises the question of where security cameras fall under this jurisdiction….time for a quick diversion:
CCTV Cameras
As CCTV involves storing images that can be used to identify people, this comes under GDPR’s definition of personal data and as such we are required to have signage in place to inform people that we are using it, and why – the images can only be captured for this limited and specific purpose (before we start thinking we can hack into the CCTV system for some test data)
Live streaming and photography at events
When we take photographs at events we put up signs saying that we are taking photographs, however whilst UK law allows you to take photos in a public place, passive content may not be acceptable under GDPR when collecting data via image recognition technology.
Gallery interactive displays
Some of our exhibition installationsinvolve live streaming – we installed a cctv camera in front of a greenscreen as part of our Early Man exhibition in order. to superimpose visitors in front of a crowd of prehistoric football supporters from the film. The images are not stored but they are processed on the fly – although it is fairly obvious what the interactive exhibit is doing, should we be asking consent before the visitor approaches the camera, or displaying a privacy notice explaining how we are processing the images?
Any solution that involves hooking up webcams to a network or the internet comes with a risk. For the purposes of this hackday we are going to be using raspberry pi connected to a webcam and using this to analyse the images. If this was to be implemented in the museum we’d need to assess the risk of the devices being intercepted .
Authentication and encryption:
Authentication – restrict data to authorised users – user name and password (i.e. consent given)
Encryption – encoding of the data stream so even if unauthenticated user accesses the stream, they can’t read it without decrypting. E.g. using SSL.
Furthermore – if we are sending personal data for analysis by a service running online, the geographic location of where this processing takes place is important.
“For GDPR purposes, Microsoft is a data processor for the following Cognitive Services, which align to privacy commitments for other Azure services”
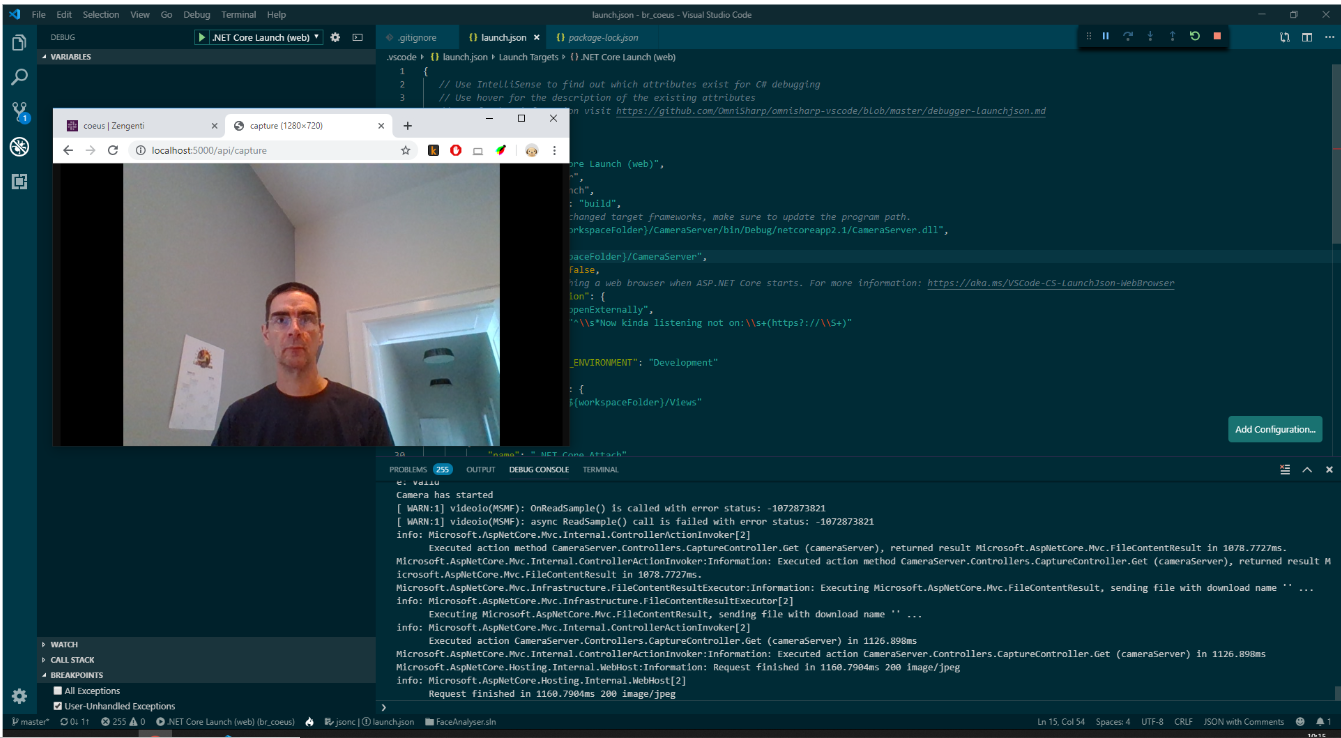
Minimum viable product: Connecting the camera server, the face analyser, the monitoring dashboard and the visualisation.
Despite the above practical considerations – the team have cracked on with assembling various parts of the solution – using a webcam linked to a Raspberry Pi to send images to the Azure Face API for analysis. Following on form that some nifty tools in data visualisation, and monitoring dashboard software can help users manage a number of devices and aggregate data from them.
There are some architectural decisions to make around where the various components sit and whether image processing is done locally, on the Pi, or on a virtual server, which could be hosted locally or in the cloud. The low processing power of the Pi could limit our options for local image analysis, but sending the images for remote processing raises privacy considerations.
Step 1: Camera server
After much head scratching we had an application that could be launched on PC or linux that could be accessed over http:// to retrieve a shot from any connected webcam – this is the first part of the puzzle sorted.
By the second day we had a series of webcam devices – raspberry Pi, windows PC stick and various laptops all providing pictures from their webcams via via http requests over wifi – so far so good – next steps are how to analyse these multiple images from multiple devices.
Step 2: Face analyser.
Because the Azure Face API is a chargeable service, we don’t want to waste money by analysing images that don’t contain faces – so we implemented some open source script to first check for any faces. If an image passses the face test – we can then send it for analysis.
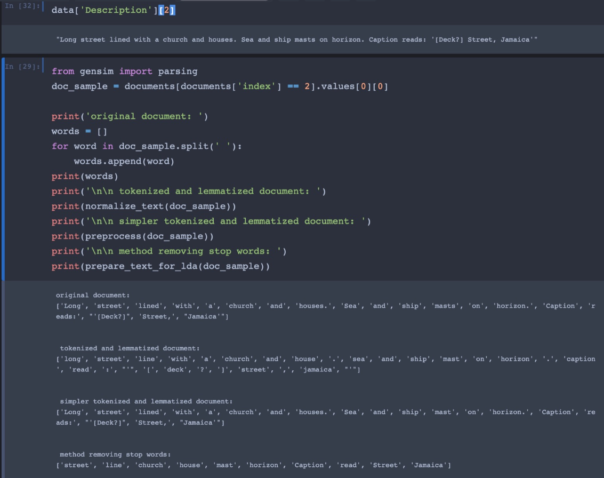
The detailed analysis that is returned in JSON format includes data on age, gender, hair colour and even emotional state of the faces in the picture.
Our first readings are pretty much on point with regards to age when we tested ourselves through our laptop webcams. And seeing the structure of the returned data gives us what we need to start thinking about the potential for visualising this data.
We were intrigued by the faceid code – does this ID relate to an individual person (which would infer the creation of a GDPR-risky person database somewhere), or simply the face within the image, and if we snapped the same people at different intervals, would they count as different people? It turns out the faceid just relates to the face in an individual image, and does not relate to tracking an individual over time – so this looks good as far as GDPR is concerned, but also limits our ability to deduce how many unique visitors we have in a space if we are taking snaphots at regular intervals.
We had originally envisaged that facial analysis of a series of images from webcams could give us metrics on headcount and dwell time. As the technology we are using requires still images captured from a webcam – we would need to take photos on a regular period to get the figures for a day.
Taking a closer look at the “emotion” JSON data reveals a range of emotional states, which when aggregated over time could give us some interesting results and raise more questions – are visitors happier on certain days of the week? Or in some galleries? Is it possible to track the emotion of individuals, albeit anonymously, during their museum experience?
In order to answer this we’d need to save these readings in a database with each recorded against a location for the location and time of day – the number of potential variables are creeping up.
We would also need to do some rigorous testing that the machine readings were reliable – which raises the question about how the Face API is calibrated in the first place…but as this is just an experiment our priority is connecting the various components – fine tuning of the solution is beyond the scope of this hack.
Step 3: Data exporter
Prometheus is the software we are using to record data over time and provide a means to query the data and make it available to incoming requests from a monitoring server. We identified the following variables that we would like to track – both to monitor uptime of each unit and also to give us useful metrics.
Essential
CPU gauge
Memory gauge
Disk Space gauge
Uptime
Uptime (seconds) counter
Services
Coeus_up (0/1) gauge
Exporter_up (0/1) gauge
Face count
current_faces (count) gauge
Face_id (id)
Total_faces (count) summary
Nice to have
Gender
male/female
Gender (0/1) gauge
Age
Age buckets >18 18<>65 <65 histogram
Dwell duration
Seconds
Dwell_duration_seconds gauge
Services
Coeus_up (0/1) gauge
Exporter_up (0/1) gauge
Coeus
API queries
API_calls (count) gauge
API_request_time (seconds) gauge
Exporter
Exporter_scrape_duration_seconds gauge
Step 4: Data dashboard
Every data point carries a timestamp and so this data can be plotted along an axis of time and displayed on a dashboard to give a real time overview of the current situation.
Step 5: Data visualisation
Using D3 we can overlay a graphic representing each face/datapoint back onto the camera feed. In our prototype mock up each face is represented by a shape giving an indication of the ir position within the fame. Upon this we could add colour or icons illustrating any of the available data from the facial analysis.
Slack: we used this for collaboration during the project – great for chat and sharing documents and links, and breakout threads for specific conversations. This became the hive of the project.
Prometheus: monitoring remote hardware
Grafana: open source dashboard software
Azure: image recognition
Codepen:a code playground
D3: visualization library
Final remarks
Our aim was to get all the bits of the solution working together into a minimum viable product – to get readings from the webcam into a dashboard. With multiple devices and operating systems there could be many different approaches to this in terms of deployment methods, network considerations and options for where to host the image processing technology. We also wanted a scalable solution that could be deployed to several webcam units.
Just getting the various pieces of the puzzle working would most likely take up the whole time as we sprinted towards our MVP. As we started getting the data back it was starting to become clear that the analysis of the data would present its own problems, not just for reliability, but how to structure it and what the possibilities are – how to glean a useful insight from the almost endless tranches of timestamped data points that the system could potentially generate, and the associated testing, configuring and calibrating that the finished solution would need.
Whilst the Azure Face API will merrily and endlessly convert webcam screenshots of museum visitors to data points – the problem we face is what to make of this. Could this system count individuals over time, and not just within a picture? It seems that to do this you need an idea of how to identify an individual amongst several screen shots using biometric data, and so this would require a biometric database to be constructed somewhere to tell you if the face is new, or a repeat visitor – not something we would really want to explore given the sensitive nature of this data.
So this leaves us with data that does not resolve to the unique number of people in a space over time, but the number of people in a single moment, which when plotted over time is something like an average – and so our dashboard would feature “the average emotional state over time” or “the average gender”. As the same individual could be snapped in different emotional states.
As ever with analytical systems the learning point here is to decide exactly on what to measure and how to analyse the data before choosing the technology – which is why hackathons are so great because the end product is not business critical and our prototype has given us some food for thought.
With GDPR presenting a barrier for experimenting with the Face API, I wonder whether we might have some fun pointing it at our museum collections to analyse the emotional states of the subjects of our paintings instead?
Bristol City Council publishes many types of raw data to be transparent about the information they hold, and to encourage positive projects based on this data by any citizen or organisation.
One of the most recent datasets to be published by Bristol Museums is thousands of images from the British Empire and Commonwealth (BEC) collection. You can see a curated selection of these images online “Empire through the Lens”.
At a hackathon hosted by Bristol’s Open Data team with support from the Jean Golding Institute, attendees were encouraged to make use of this new dataset. Our team formed around an idea of using image style transfer, a process of transforming the artistic style of one image based on another using Convolutional Neural Networks.
In layman’s terms this method breaks down images into ‘content’ components and ‘style’ components, then combines them.
We hypothesised there would be value in restyling images from the dataset to draw out themes of Bristol’s economic and cultural history when it comes to Empire and Commonwealth.
The team
Dave Rowe – Development Technical Lead for Bristol City Council and Open Data enthusiast
Junfan Huang – MSc Mathematics of Cybersecurity student in University of Bristol
Mark Pajak – Head of Digital at Bristol City Council Culture Team & Bristol Museums
Rob Griffiths – Bristol resident andArtificial Intelligence Consultant for BJSS in the South West
Aim
To assess the potential of Style Transfer as a technique for bringing attention back to historical images and exploring aspects of their modern relevance.
Method
Natalie Thurlby from the Jean Golding Institute introduced us to a method of style transfer using Lucid, a set of open source tools for working with neural networks. You can view the full Colab notebook we used here.
To start with, we hand-selected images from the collection we thought it would be interesting to transform. We tried to pair each ‘content’ image with ‘style’ images that might draw parallels with Bristol.
Dockside Cranes
A railway steam crane lowers a train engine onto a bogie on the dockside at Kilindini harbour, Mombasa, Kenya.
When we saw this image it immediately made us think of the docks at Bristol harbourside, by the Mshed.
The SS Harmonides which transported the train [likely from Liverpool actually] to Kenya is just visible, docked further along the harbour.
In addition to the images, the data set has keywords and descriptions which provide a useful way to search and filter
We liked this painting by Mark Buck called the Cranes of Bristol Harbour. It says online that Mark studied for a degree in illustration at Bower Ashton Art College in Bristol, not too far from this place.
This image has been created as a result of adding the previous two images into the style tranfer engine.
We drew an obvious parallel here between these two sets of cranes in ports around the world. The Bristol cranes are from the 1950s, but the Kenya photo was taken much earlier, in the 1920s It would be interesting to look more deeply at the cargo flows between these two ports during the 19th century.
Cliftonwood Palace
This is a view of the Victoria Memorial, Kolkata, India in 1921.
It was commissioned by Lord Curzon to commemorate the death of Queen Victoria.
We were struck by the grandeur and formality of the photo.
A photo of the colourful Victorian terraces of Cliftonwood from the river, which have their own sense of formality.
The architectural significance of these buildings in their locales and link to Queen Victoria are small parallels.
It’s funny how the system seemingly tries to reconstruct the grand building using these houses as colourful building blocks, but it ends up making it look like a shanty town.
This image was created by machine intelligence by taking an historical photograph and applying a style gleaned from a bristol cityscape.
Caribbean Carnival
Carnival dancers on Nevis, the island in the Caribbean Sea, in 1965.
Two men perform a carnival dance outdoors, accompanied by a musical band. Both dancers wear crowns adorned with peacock feathers and costumes made from ribbons and scarves.
St Pauls Carnival is an annual African-Caribbean carnival held, usually on the first Saturday of July, in St Pauls, Bristol.
We selected this picture to see how the system would handle the colourful feathers and sequined outfits.
The resulting image (below) was somewhat abstract but we agreed was transformed by the vibrant colours and patterns of movement.
Festival colours reimagine an historical photograph using machine intelligence – but is this a valid interpretation of the past or an abstract and meaningless picture?
After generating many examples we came together to discuss some of the ethical and legal implications of this technique.
We were particularly mindful of the fact that any discussion of Empire and Commonwealth should be treated with sensitivity. For each image, it’s challenging both to appreciate fully the context and not to project novelty or inappropriate meaning onto it.
We wondered whether this form of style transfer with heritage images was an interesting technique for people who have something to say and want an eye-catching way of communicating, but not a technique that should be used lightly – particularly with this dataset.
We often found ourselves coming back to discussions of media rights and intellectual property. None of us have a legal background but we were aware that, while we wanted to acknowledge where we had borrowed other people’s work to perform this experiment, we were generating new works of art – and it was unclear where the ownership lay.
Service Design
We set out potential benefits of our service:
A hosted online service to make it a more efficient process
Advice and tips on how to calibrate and get the best results from Style Transfer
Ability to process images in bulk
Interactive ways of browsing the dataset
Communication tools for publishing and sharing results
Interfaces for public engagement with the tool – a Twitter conversational bot
On the first day we started putting together ideas for how a web service might be used to take source images from the Open Data Platform and automate the style stransfer process.
This caused us to think about potential users of the system and what debate might be sparked fromt he resulting images.
Proposition Design
A key requirement for all users would be the ability to explore and see the photographs in their original digitised form, with the available descriptions and other metadata. Those particularly interested in exploring the underlying data would appreciate having search and filter facilities that made use of fields such as location, date, and descriptions.
We would also need a simple way of choosing a set of photographs, without getting in the way of being able to continue to discover other photos. A bit like in an online shopping scenario where you add items to a basket.
The users could then choose a style to apply to their chosen photos. This would be a selection of Bristol artworks, or iconic scenes. For those wanting to apply their own style (artists, for example) we would give an option to upload their own artwork and images.
Depending on processing power, we know that such an online service could have difficulty applying style transforms in an appropriate time for people to wait. If the waiting time were over a couple of minutes it could be that the results are provided by email.
Components
Spin off products…Topic Modelling
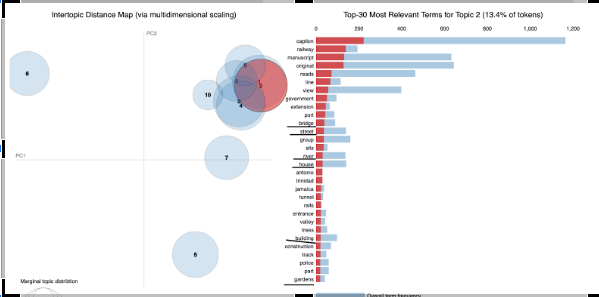
We even successfully built a crucial component of our future service. The metadata surrounding the images includes both keywords and descriptive text. Junfan developed a script that analysed the metadata to provide a better understanding of the range of keywords that could be used to interrogate the images. This could potentially be used in the application to enable browsing by subject….
We wanted to generate a list of keywords from the long form text captions that accompanied the images. This would allow us to come up with a classification for pictures using their description. Then, users would be able to select topics and get some pictures they want.
Here in topic 2, our model has added bridge, street, river, house, gardens and some similar words into the same group.
Python is the language of choice for this particular applicationTopic modelling reveals patterns of keyword abundance amongst the captionskeywords extracted from the captions can help us build an interface to allow filtering on a theme
Reflections
After generating many examples we came together to discuss some of the ethical and legal implications of this technique.
We were particularly mindful of the fact that any discussion of Empire and Commonwealth should be treated with sensitivity. For each image, it’s challenging both to appreciate fully the context and not to project novelty or inappropriate meaning onto it.
We wondered whether this form of style transfer with heritage images was an interesting technique for people who have something to say and want an eye-catching way of communicating, but not a technique that should be used lightly – particularly with this dataset.
We often found ourselves coming back to discussions of media rights and intellectual property. None of us have a legal background but we were aware that, while we wanted to acknowledge where we had borrowed other people’s work to perform this experiment, we were generating new works of art – and it was unclear where the ownership lay.
Does this have potential?
We thought, on balance, yes this was an interesting technique for both artistic historians and artists interested in history.
We imagined their needs using the following user personas:
Artistic Historians: ‘I want to explore the stories behind these images and bring them to life in a contemporary way for my audience.’
Artists interested in history: ‘I want a creative tool to provide inspiration and see what my own personal, artistic style would look like applied to heritage images’.
We spent time scoping ways we could turn our work so far into a service to support these user groups.
References & Links
The repo for our application: https://github.com/xihajun/Art-vs-History-Open-Data-Hackathon-Code
Open data platform:https://opendata.bristol.gov.uk/pages/homepage/
Bristol Archives (British Empire and Commonwealth Collection): https://www.bristolmuseums.org.uk/bristol-archives/whats-at/our-collections/
Acknowledgements
Thanks to Bristol Open for co-ordinating the Hackathon.
Thanks to Lucid contributors for developing the Style Transfer code.
Thanks to the following artists for source artwork:
Mark Buck: https://www.painters-online.co.uk/artist/markbuck
Hi, my name is Hannah Boast and I am an apprentice working in the City Innovation Team for Bristol City Council. Our aim as a team is to create a smarter digital future for Bristol. A wide range of projects are currently being worked on by the City Innovation team such as driverless cars, smart homes and ultrafast broadband. A project I would like to elaborate on which our team is also involved in is maintaining and promoting the Open Data platform.
Bristol’s open data platform’s objective is to have accessible data that is widely available to the public and to organisations. By increasing data transparency it can open opportunities for discovering new insights of the city and support our digital economy. Successfully we have recently been co-ordinating data hackathons and data jams which involve gathering people who collaboratively code over a short period of time. During this attendees will be working on a particular project and the idea is for the teams to have the ability and freedom to work on whatever he/she wants. These engagements run along with contributing partners such as organisations and the data community. The data engagements can help us understand the aims of the interested public in open data and bringing in a new generation of people who can help drive and contribute to open data in Bristol. Keep up to date on any upcoming events on our Connecting Bristol website.
Bristol Museum & Art gallery are currently digitalising their collection of artefacts to make it accessible to a wide range of people online. A great example is The Natural History Museum data portal it has uploaded a great deal of the museums artefacts. This gives the public access to find out more detailed information on what is held at the museum.
Get in contact with us to find out more on open data in Bristol: opendata@bristol.gov.uk
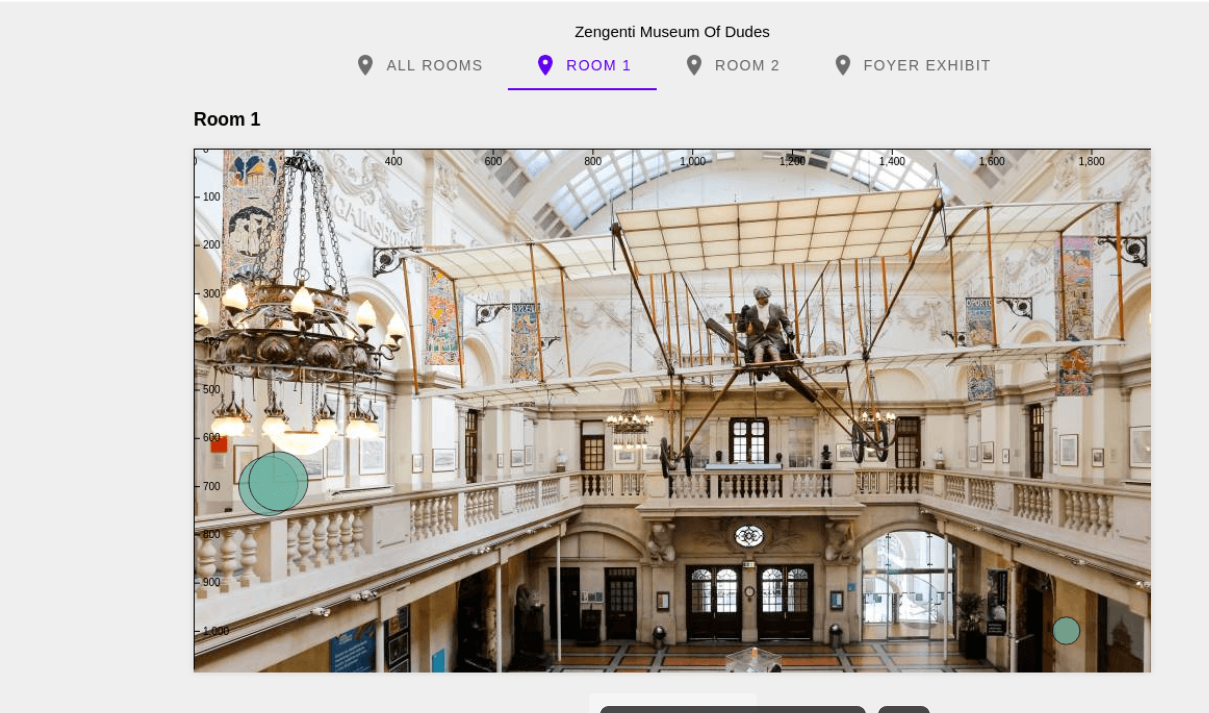
Over the next few weeks we are running user testing of SMARTIFY at M Shed. This app provides visitors with extra information about museum objects using image recognition to trigger the content on a mobile device.
To install the free app use this link: https://smartify.org/
If you have used the app at M Shed, please could you take a few moments to complete the following survey: https://www.surveymonkey.co.uk/r/ZVTVPW9
If you would like to help further, please get in touch with our volunteer co-ordinator: https://www.bristolmuseums.org.uk/jobs-volunteering/
Our temporary exhibitions have around a 20% conversion rate on average. While we feel this is good (temporary exhibitions are either paid entry or ‘pay what you think’, bringing in much-needed income), flip that around and it means that around 80% of people are visiting what we call our ‘permanent galleries’ – spaces that change much less often than exhibitions. With a million visitors every year across all of our sites (but concentrated at M Shed and Bristol Museum & Art Gallery), that’s a lot of people.
A lot of our time as a digital team is taken up with temporary exhibitions at M Shed and Bristol Museum. Especially so for Zahid, our Content Designer, who looks after all of our AV and whose time is taken up with installs, derigs and AV support.
But what about all of the digital interpretation in our permanent galleries? Focusing on the two main museums mentioned above, we’ve got a wide range of interp such as info screens, QR codes triggering content, audio guides and kiosks. A lot of this is legacy stuff which we don’t actively update, either in terms of content or software/hardware. Other bits are newer – things we’ve been testing out or one-off installs.
So, how do we know what’s working? How do we know what we should be replacing digital interp with when it’s come to the end of its life – *IF* we should replace it at all? How do we know where we should focus our limited time (and money) for optimal visitor experience?
We’ve just started some discovery phases to collate all of our evidence and to gather more. We want a bigger picture of what’s successful and what isn’t. We need to be clear on how we can be as accessible as possible. We want to know what tech is worth investing in (in terms of money and time) and what isn’t. This is an important phase of work for us which will inform how we do digital interpretation in the future – backed up by user research.
Discovery phases
We’ve set out a number of six week stints from August 2018 to January 2019 to gather data, starting with an audit of what we have, analytics and what evidence or data we collect.
We’ll then move onto looking at specific galleries– the Egypt Gallery at Bristol Museum and most of the galleries at M Shed which have a lot of kiosks with legacy content. (The M Shed kiosks probably need a separate post in themselves. They were installed for when the museum opened in 2011, and since then technology and user behaviours have changed drastically. There’s a lot we could reflect on around design intentions vs reality vs content…)
We’ll also be gathering evidence on any audio content across all of our sites, looking at using ourexhibitions online as interp within galleries and working on the Smartify app as part of the 5G testing at M Shed.
We’re using this trello board to manage the project, if you want to follow what we’re doing.
Auditing our digital interpretation
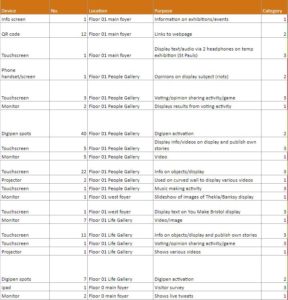
First off, we simply needed to know what we have in the galleries. Our apprentice Rowan kindly went around and scoured the galleries, listing every single thing she could find – from QR codes to interactive games.
We then categorised everything, coming up with the below categories. This has really helped to give an overview of what we’re working with.
Key
Level of interaction
Examples
User control
1
Passive
Auto play / looping video, static digital label, info screens
User has no control
2
Initiate
QR code / URL to extra content, audio guide
User triggers content, mostly on own or separate device
3
Active
Games and puzzles, timeline
User has complete control. Device in gallery
We then went through and listed what analytics we currently gather for each item or what action we need to take to set them up. Some things, such as info screens are ‘passive’ so we wouldn’t gather usage data for. Other things such as games built with Flash andDiscoveryPENs (accessible devices for audio tours), don’t have in-built analytics so we’ll need to ask our front of house teams to gather evidence and feedback from users. We’ll also be doing a load of observations in the galleries.
Now that people have devices in their pockets more powerful than a lot of the legacy digital interpretation in our galleries, should we be moving towards a focus on creating content for use on ‘BYO devices’ instead of installing tech on-site which will inevitably be out of date in a few short years? Is this a more accessible way of doing digital interpretation?
Let us know what you think or if you have any evidence you’re happy to share with us. I’d be really interested to hear back from museums (or any visitor attractions really) of varying sizes. We’ll keep you updated with what we find out.
Any other museum digital people getting an influx of requests for QR codes to put in galleries recently? No? IS IT JUST US?!
After thinking that QR codes had died a death a few years ago, over the last few months we’ve had people from lots of different teams ask for QR codes to trigger content in galleries, for a variety of uses such as:
Sending people to additional content to what’s in an exhibition, to be used while in the gallery e.g. an audio guide
Showing the same content that’s in the exhibition but ‘just in case’ people want to look at it on their phones
Sending people to content that is referenced in exhibitions/galleries that needs a screen but doesn’t have an interactive e.g. a map on Know Your Place
After an attempt to fend them off we realised that we didn’t really have any evidence that people don’t use them. At least nothing recent or since the introduction of automatic QR code scanning with iOS 11 last year (thanks for that, Apple). So, we thought we’d test it out, making sure we’re tracking everything and also always providing a short URL for people to type into browsers as an alternative.
In most cases, it’s as expected and people just aren’t using them. They’re also not using the URL alternatives either, though, which maybe suggests that people don’t really want to have to go on their phones to look at content and are happy with reading the interpretation in the gallery. Controversial, I know. (Or maybe we need to provide more appealing content.)
However, then we come to our recent Grayson Perry exhibition at Bristol Museum & Art Gallery, which had audio content which was ‘extra’ to what was in the exhibition. We provided headphones but visitors used their own devices. A key difference with this one though was that our front of house team facilitated use of the QR codes, encouraging visitors to use them and showing them what to do. As such, the six audio files (there was one with each tapestry on display) had 5,520 listens altogether over the course of the exhibition (March – June), over 900 each on average.
Whilst it’s great that they were used – it threw us a bit – the flip side of this is that it was only in an instance where it’s being facilitated. I’m not partuclarly keen on using something that we’re having to teach visitors how to use and where we’re trying to change users’ behaviours.
There’s also some more here around the crossover between online and gallery content (should we be using one thing for both, are they different user cases that need to be separate) which we’re talking about and testing more and more at the moment, but that’s one for another post.
We’d be really interested to hear your thoughts on triggered content. Do people even know what QR codes are? Are ‘just because we can and they’re no/low cost’ reasons enough to use them? How do you do triggered content? Is this unique to medium-sized museums or are the big and smaller guys grappling with this too? Or is it really just us?!

























 But what about all of the digital interpretation in our permanent galleries? Focusing on the two main museums mentioned above, we’ve got a wide range of interp such as info screens,
But what about all of the digital interpretation in our permanent galleries? Focusing on the two main museums mentioned above, we’ve got a wide range of interp such as info screens,