I have been working on the development of the Bristol Museums partner page with Google Arts & Culture for close to two years, and in October it finally went live!
Some background info about my involvement
I started working on this as a trainee on the Museum Futures programme in January 2020, this was actually one of the first projects that I participated on. Originally designed as a partnership with South West Museum Development , the idea behind it was that we would develop a page for Bristol Museums and then bring this (and the process guides) to smaller museums as a way to support getting their collections online. However, it was mutually decided that this process was more convoluted than anyone first assumed, and that didn’t end up happening.
As of April 2021, I have continued to work on this in my current role as Digital Collections Content Coordinator – a position funded by the Art Fund – as part of a larger project to make our collections accessible online. Thanks Art Fund!
This project has not necessarily gone to plan. We originally aimed to launch at some point in summer 2020. We were then offered to be a part of the Google Arts & Culture Black History Month 2020 campaign if we were ready to launch by that October. While we first worked towards meeting the deadline, we ultimately decided against going ahead with this plan as we had to rush, and we felt that these stories deserved a much longer preparation time than we could give them at that stage. Also, we felt that we didn’t need to be a part of the campaign in order to tell these stories.
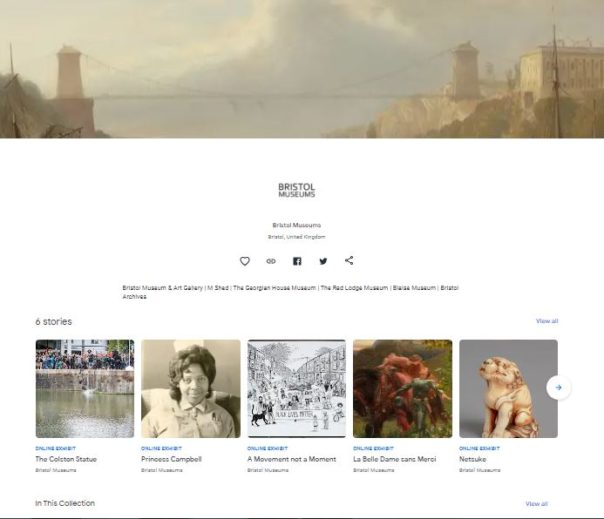
What is Google Arts & Culture?
Google Arts & Culture is still fairly new and unknown territory, and there seem to be a number of (understandable) misconceptions about what its purpose is. Is it social media? Is it an alternative to Collections Online? Is it a blog? Can we signpost to events and the shop?
No, sort of but not really, no and no.
This doesn’t really sound appealing, does it?
The best comparison we can make is to a Collections Online service, but less extensive. And it’s shared by lots of other organisations. And also other organisations can use our images. (Yikes! But bear with me.)
It is described as an online platform through which the public can view high resolution images of objects in museums and galleries. This is accurate, does what it says on the tin.
You might know Google Arts & Culture from the Art Selfies trend (which I would recommend checking out if you’re not easily offended, as the comparisons are usually NOT KIND) or the chance to zoom in reeeeeally close to Rembrandt’s The Night Watch. These are two of the platform’s jazzy features that haven’t really been seen anywhere before, at least not in the same way.
Why do we want to use it?
They use incredibly sophisticated software to automatically attach these functions to uploaded content, which is good for us because it means we don’t have to do anything special to get them to work for our objects. By using the highest quality TIFFs that we have for the objects we’ve selected, we can zoom in to brushstroke level on these works and use attention grabbing features like an interactive timeline.

I mentioned before that other people can use our images. This sounds like a big no-no, but bear with me (again).
When creating an exhibition or a story you can use content that you’ve previously uploaded, but you also have the opportunity to use images shared by other organisations. This is often used if an org is creating a story about a specific subject and they don’t have enough content/images to contextualise, they can use images that have been uploaded to the platform previously. As all images already have clear rights acknowledgements and redirect to the partner page they belong to, this does not breach anything nasty.
The benefit of this is that the reach one image could potentially have is boundless, and thus, the reach of our page also has the potential to be boundless.
What do we do if they kill it?
Well, it wouldn’t be ideal. We wouldn’t lose much content, and we won’t lose any data as this all came from our CMS anyway. We don’t rely on this to attract the bulk of our audiences and we’ve approached it as a bit of an experiment. It would be a shame to lose it, but it’s so new that I honestly can’t say how much of an impact that it would have, so I suppose we’ll just have to wait and see.
What has the process been to make it a thing here?
LONG. This process has been full of learning curves and a lot of troubleshooting. There is much to be said for data consistency and quality at internal database level when working on projects such as this. Arguably, one of the longest processes is assessing groups of content to ensure that what you’re including meets data requirements. But it has been fun to experiment and uncover a process that is now…somewhat…streamlined – which looks a bit like this:
- Find cool things on the database
- Export cool things using a self-formatting report that you’ve spent weeks developing in Visual Basic (groan)
- Find images of cool things and group those
- Export images of cool things using another self-formatting report that you’ve spent weeks developing in Visual Basic (more groaning)
- Stitch together image metadata and object metadata
- Add in descriptions and dimensions data manually because of data quality issues and duplicates that you have to assess on a case by case basis
- Upload fully formatted and cleaned dataset to a Google Drive as a Google Sheet
- Add in rows from new dataset into the Google Sheet that you’ve been provided with, because instead of uploading individual CSVs (which it says you can do but this option does not work) you have to use one spreadsheet and refresh it every time you make additions from the Cultural Institute (Google A&C back end)
- Upload images to Google Bucket
- Refresh spreadsheet from the Cultural Institute
- Fix all of the errors that it comes up with because it’s a buggy system
- Refresh again
- Repeat steps 11 and 12 as needed
So…not exactly streamlined but in fairness, I have ironed out all of the kinks that I am capable of ironing out. The systems designed by Google are more archaic in practice than I was anticipating (sorry Google, no shade) and the small yet very irritating tech issues were real roadblocks at times. And yet, we persevere.
There will always be a level of manual work involved in this process, as there should be when it comes to choosing images and reviewing content, but I think that this does highlight areas where we could do with giving our database some TLC – as if that’s an easy and quick solution that doesn’t require time, money and other resources…
We aren’t sure what the future of the Bristol Museums partner page looks like just yet, especially with a few projects in the works that might help us bridge some of the gap that Google Arts & Culture is helping to fill. At the very least, I’ve learned a fair bit about data movement and adaptability.
Do have a look! This was a labour of love and stubbornness. Maybe let us know what you think?